
This blog belongs to a series on GPUBreach. This article covers Lateral Movement, Collection and Impact: how an unprivileged container process can lead to GPU read/write access. Head here to read our validation of GPUBreach and how it achieves Privilege Escalation and Resource Hijacking / Escape to Host: the corruption of a NVIDIA driver and a root shell on the host.
An unprivileged process running inside a CUDA container can gain arbitrary read/write to every byte of VRAM on a shared GPU. Model theft, model poisoning and the accessing of private user data and inference data — all possible. That's just the first half of this attack. It doesn't require special permissions, no kernel exploits, in fact, nothing your security team would flag… From an unprivileged process to corrupted NVIDIA drivers and escalation to root on the host. Let's dive in.
It's a demonstrated attack method, responsibly disclosed to NVIDIA, Google, AWS, and Microsoft, and presented at IEEE S&P 2026 by researchers from the University of Toronto.
Critically, this attack cannot be seen by endpoint security. It's not a tuning gap or lack of signatures or behavioural analysis. Architectural restrictions of current tooling prevent GPU security visibility.
GPUs are the least instrumented, yet most privileged compute layer in modern infrastructure. Traditional security has focused entirely on CPU, network, and OS-level controls. The result is GPU-blindness. Security operations teams have no alerts, no detections, and no signals tied to what is actually executing on the GPU. Infrastructure teams are paying for HPC they cannot monitor. AI/ML teams have no runtime guardrails. Leadership cannot validate risk in their most critical compute layer.
GPUBreach is a precise illustration of what that blind spot costs.
The Attack in Three Phases
GPUBreach unfolds in three phases.
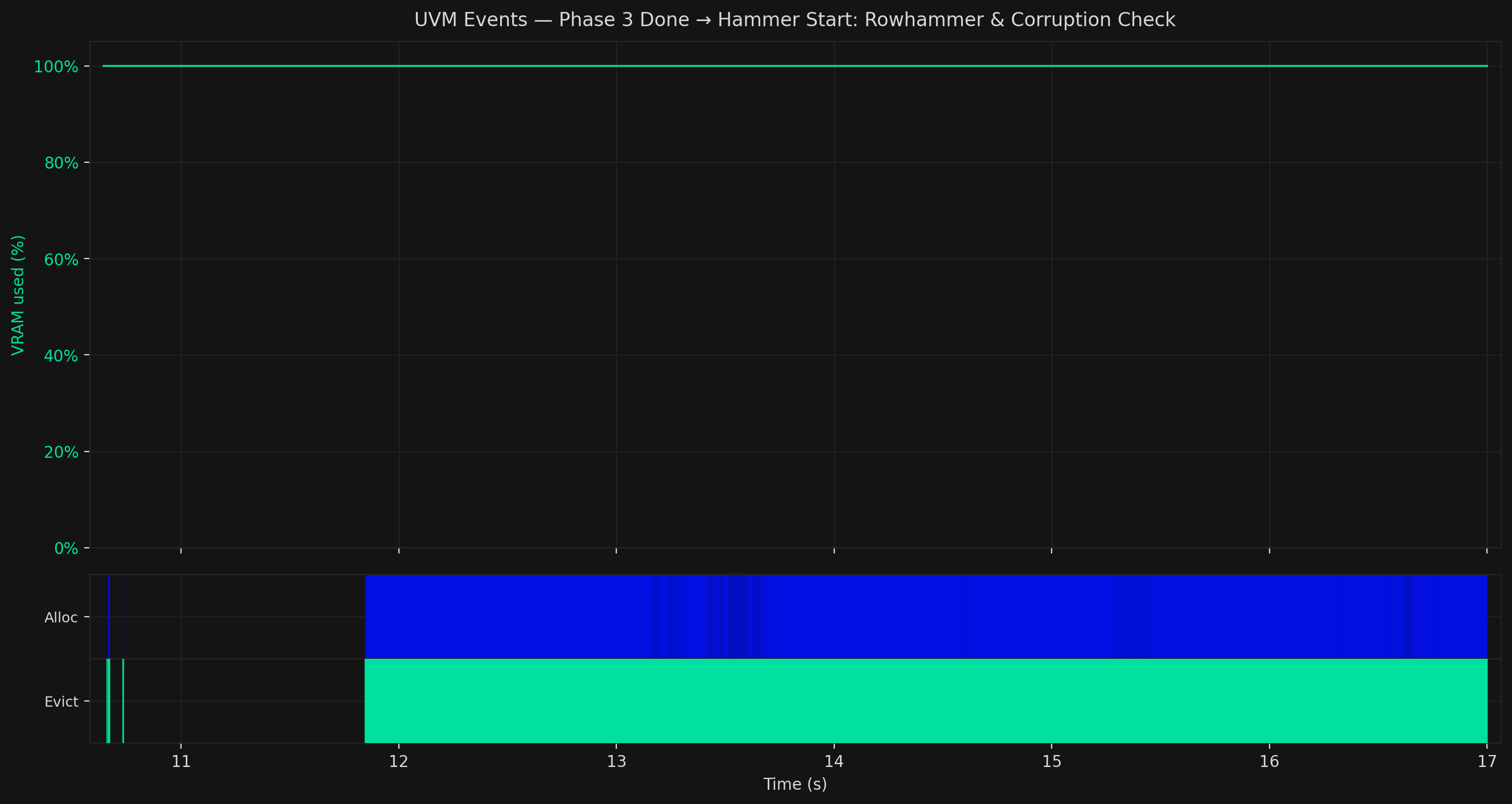
The chart below shows the full attack recorded from a live run, tracking GPU memory usage and UVM events across all four operational stages.
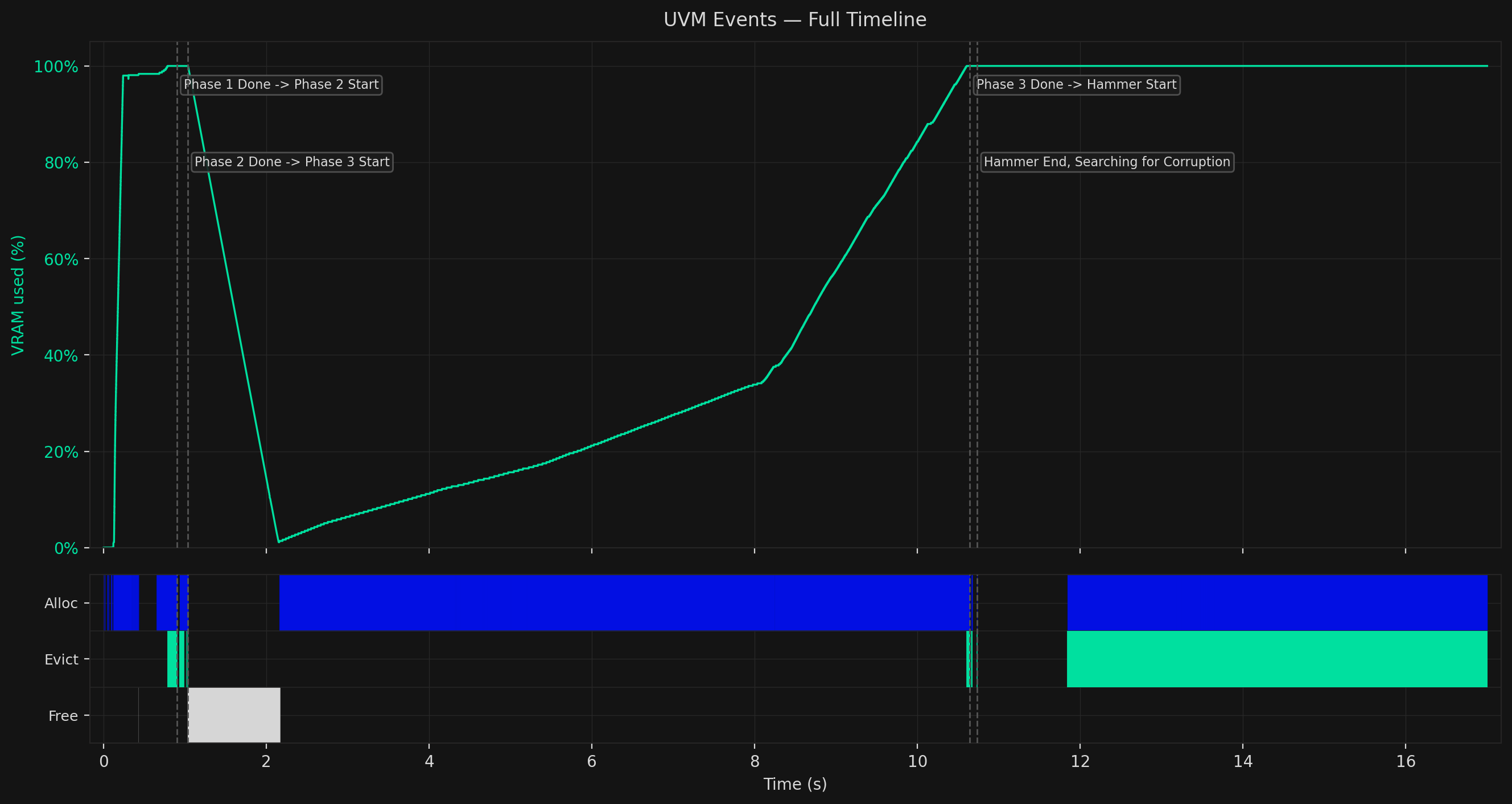
Each phase has a distinct signature. The VRAM line tells the story at a glance; the event rows underneath tell you exactly what the attacker is doing and why.
Foundational to this attack is an understanding of how the Rowhammer technique (part of GPUBreach) leverages Unified Virtual Memory (UVM) and GPU Page Tables.
Unified Virtual Memory
The attack's foundation is a GPU feature designed for developer convenience: Unified Virtual Memory (UVM).
When you allocate memory with cudaMallocManaged, the GPU and CPU share a single virtual address space. The runtime transparently moves pages between CPU and GPU as needed. When GPU memory fills up, the driver evicts the least-recently-used pages back to CPU RAM to make room.
Two properties of UVM are what make GPUBreach possible.
Evictions are slow and measurable. Moving a page across the PCIe bus is expensive. The first access to an evicted page is noticeably slower than a normal GPU memory access. An unprivileged CUDA kernel can measure this latency, and from the spikes, infer when GPU memory is full and when the driver is creating new internal data structures.
UVM supports small page sizes. The GPU driver normally promotes allocations to 2MB pages. But UVM initially allocates 4KB and 64KB pages and delays coalescing them. Specific allocation patterns hold the driver in this small-page state, which turns out to be essential for what comes next.
GPU Page Tables
Like CPUs, GPUs use page tables to translate virtual addresses to physical memory locations. Every process running on the GPU has its own page tables stored in VRAM. Each entry, a Page Table Entry (PTE), holds the physical address of a memory page.
By corrupting just one PTE so it points to a second page table page, the attacker then controls that second page table's entries. This gives them the ability to map any virtual address to any physical location in VRAM. That's arbitrary read/write access to everything on the GPU.
Phase 1: Overloading Memory and Silent Spills
The first visible signal of this attack can be found in your VRAM, as it climbs from 0% to 100%. It's an attacker flooding your GPU memory with UVM allocations. The large blue Alloc block in the event row reflects the continuous stream of small-page allocations driving the fill.
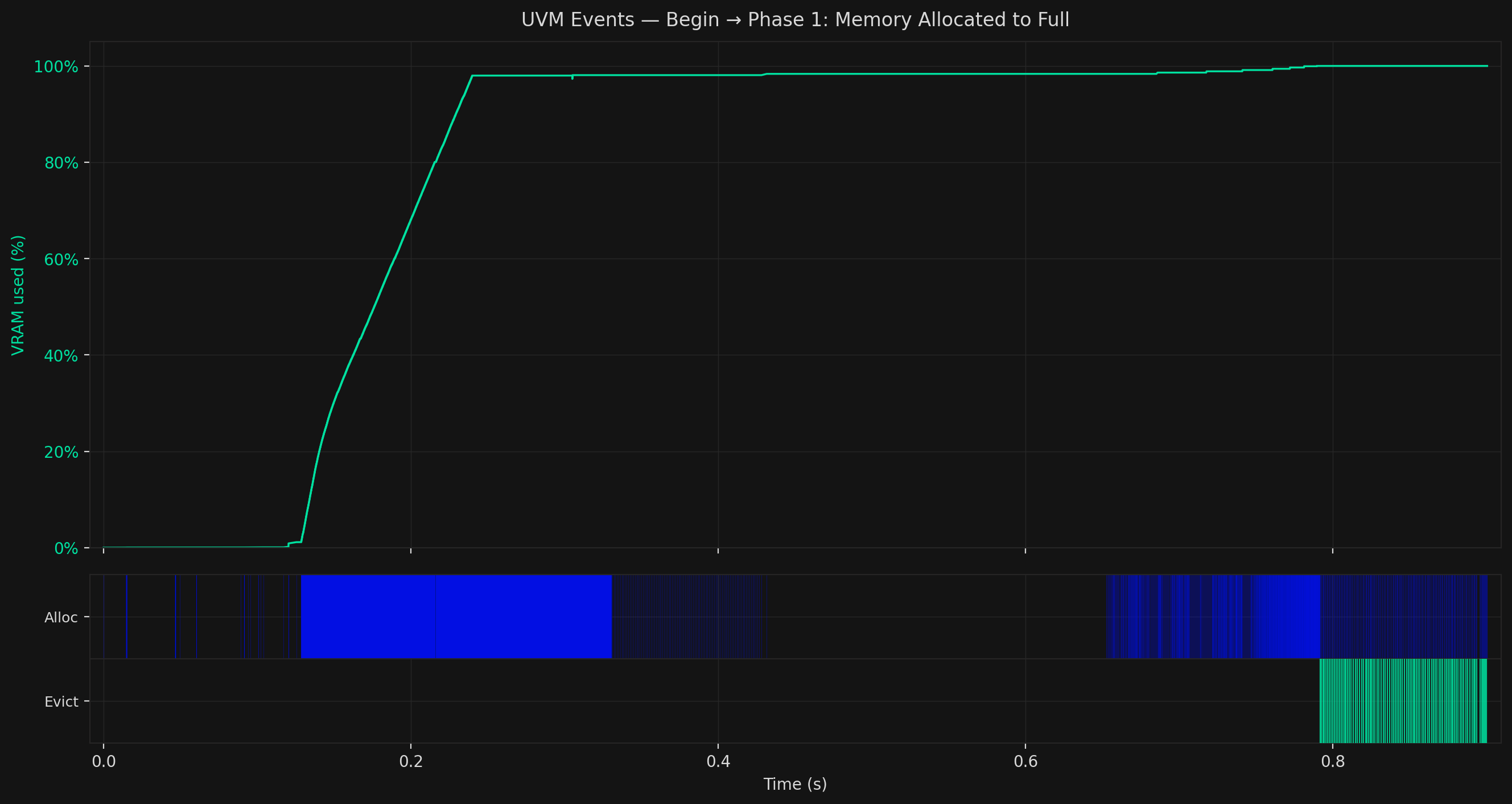
Under memory pressure, an attacker begins to influence page tables, our next phase.
For now, the attacker needs to steer the driver's internal allocator to place a new page table block at a specific physical address, one known from prior profiling to be susceptible to bit-flips. That steering only becomes possible once VRAM is completely occupied.
cudaMallocManaged does not error when VRAM runs out, there's a silent spill of UVM to CPU RAM. While the attacker has no direct way to know when the GPU is full, latency provides a signal. Once evictions start appearing consistently alongside allocations, they know VRAM is saturated and move on.
Phase 2: Page Table Massaging
While VRAM stays at 100%, the event pattern shifts: rapid, alternating Alloc and Evict events firing in tight succession.
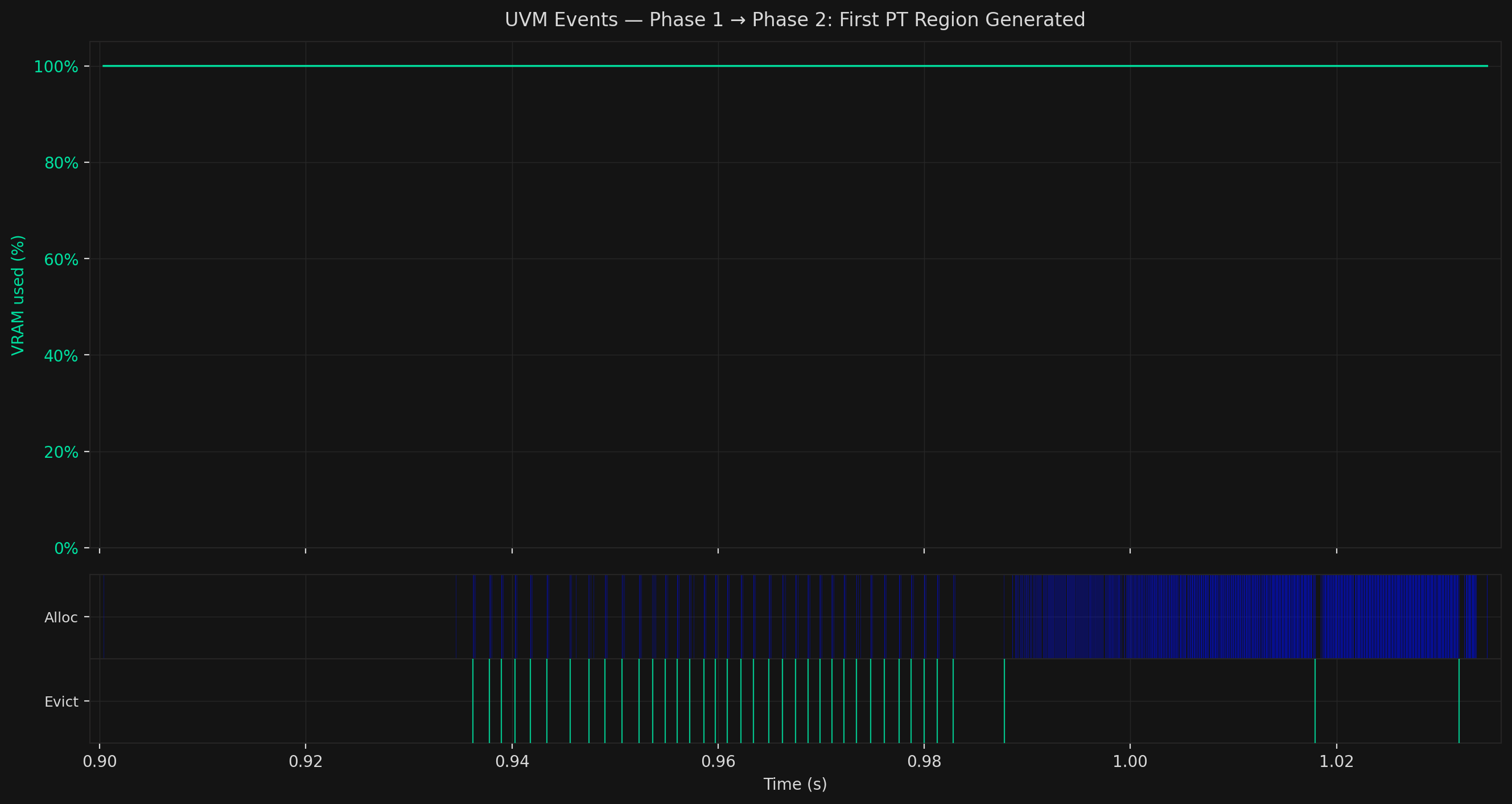
This is page table massaging. GPU page tables are allocated in contiguous 2MB blocks. The first such block lands far from user data. But once it fills, subsequent blocks are allocated from the same physical memory pool as user data, meaning they can land adjacent to DRAM rows the attacker controls. Rowhammer requires that physical adjacency.
The attacker runs a tight evict-reallocate cycle: evict an attacker-controlled data page from GPU to CPU, allocate a new one in its place, repeat. Each cycle advances the driver's allocator one slot. The attacker monitors access latency to detect when the allocator is one step away from creating a new page table block, then times a final eviction to leave the target vulnerable frame as the only available slot. The driver fills it with the new page table.
The rapid Alloc/Evict alternation is that steering loop. It completes quickly, which is why this phase appears as a narrow window between the two closest separator lines in the full timeline.
Phase 3: Free, Refill, and Hammering
Then a dramatic change as VRAM drops sharply from 100% to near zero, then climbs steadily back up. The attacker clears out their Phase 1 data pages and rebuilds in a specific pattern designed to pack the page table at the target location as densely as possible.
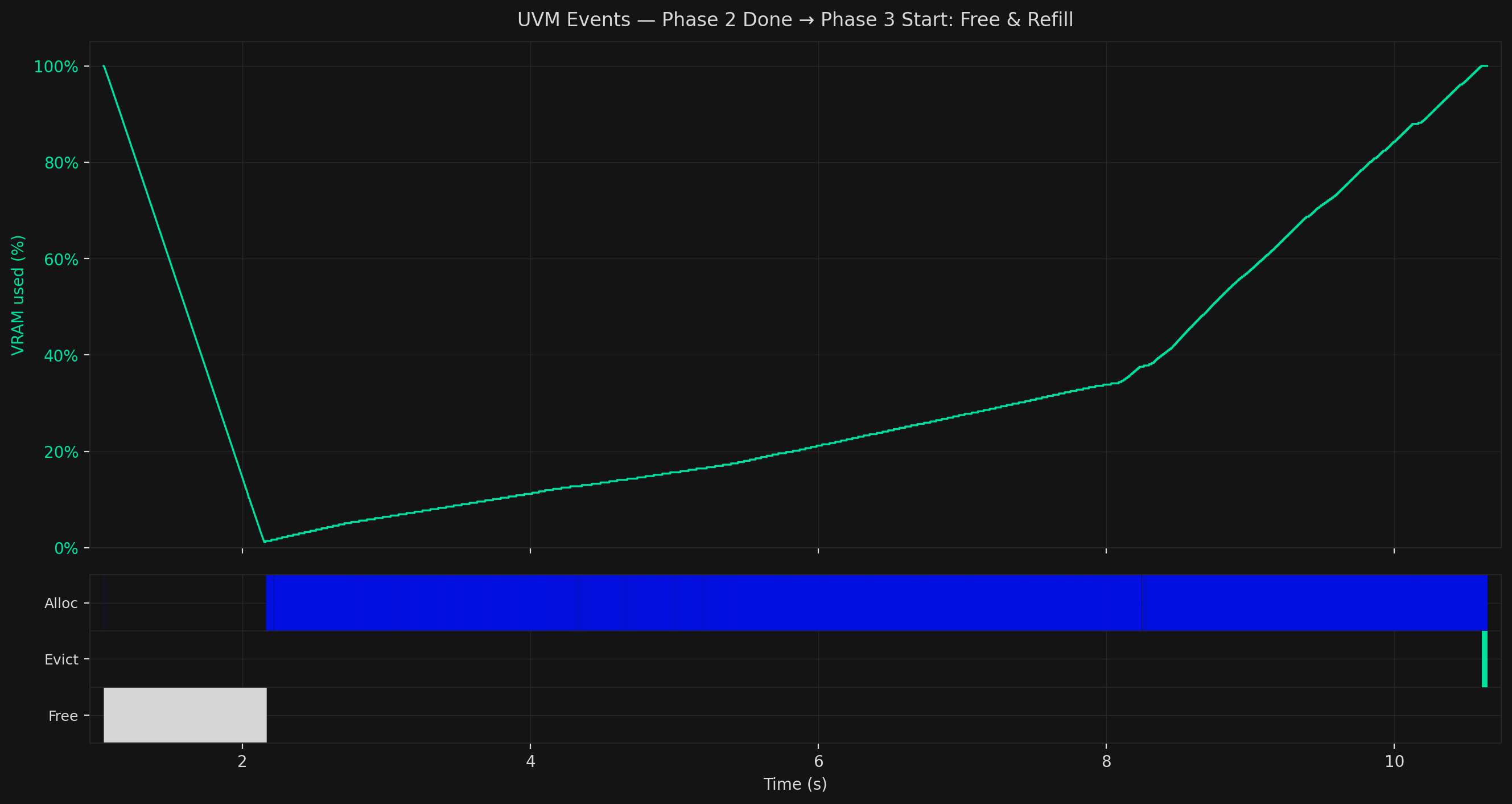
Rowhammer bit-flips are probabilistic, they hit somewhere in a victim DRAM row, not a chosen bit. Packing 31 out of 32 PTE slots in each page maximises the chance that wherever the flip lands, it corrupts a valid PTE rather than empty space.
Then the active Rowhammer campaign begins. A synchronised GPU kernel hammers the DRAM rows adjacent to the page table, inducing charge leakage into the row containing the PTEs. Simultaneously, the attacker cycles aggressor pages through GPU memory to maintain hammering pressure while keeping target pages pinned.
After hammering, the attacker scans for signs of success, looking for corrupted data pages. Each page carries a unique sequential identifier. Reading them back in virtual-address order, any out-of-sequence identifier signals a redirected PTE. They've done it. That identifier tells the attacker exactly which physical page the corrupted PTE now points to.
If that destination is attacker-controlled: they evict it, steer a new page table block to that exact physical frame (repeating Phase 2), and gain control over a second page table. They can now set any PTE to point at any physical frame in VRAM. Arbitrary read/write access. From here they can access model weights, inference data, access the Key-Value cache which may include private user data.
In practice, a usable corruption appears after roughly two hammer attempts.
For those seeking further Privilege Escalation and Escape to Host — everything so far is a prerequisite for the CPU-side escalation we detail further here.
How Stealthium Stops It Early
Every phase of GPUBreach above relies on UVM. That is also exactly where Stealthium stops it.
Stealthium instruments the NVIDIA driver directly, producing a real-time event stream for every GPU process: every allocation, eviction, and free, with process ID, chunk size, physical address, and timestamp. We analyze them all.
{
"type": "UvmEvent",
"ts": 1777287766242561500,
"data": {
"pid": 39617,
"nsproxy": 18446744072523153000,
"cgroup": 1,
"kind": "EvictStart",
"num_chunks": 1,
"chunk_size": 2097152,
"phys_addr": 658505728,
"nv_status": 0
}
}
An example of a UVM event collected by Stealthium.
For Stealthium, GPUBreach has recognisable fingerprints. The first collection of these are in the stream that appears during Phase 1, long before Rowhammer ever fires in later Phases.
This first signal is page size. Normal CUDA workloads use cudaMalloc, which produces 2MB-aligned allocations. GPUBreach requires 4KB and 64KB UVM pages to exploit the driver's small-page behaviour. No legitimate ML workload floods VRAM exclusively through small UVM pages. Stealthium flags it.
The second signal is allocation cadence. The 2MB+4KB interleaving pattern that makes page table filling practical leaves a specific footprint: repeated tight pairings of a 4KB allocation followed immediately by a 2MB eviction. At 64KB the same pairing appears at a different cadence. Both patterns are distinct sub-signatures within the Phase 1 event stream. Neither appears in any normal GPU workload.
By the time the VRAM fill completes, a process running GPUBreach has generated hundreds of these paired events. Stealthium has classified and terminated it before Phase 2 even begins. That's before any page table has been steered, and long before Rowhammer is attempted. Read/Write on your most sensitive data, prevented.
Additionally, and further detailed here, Stealthium also actively blocks the out-of-bounds write needed to corrupt the GPU driver's kernel structures on the CPU. The visibility, detection and response to this attack is covered end to end.
The Bigger Point
GPUBreach is one attack against one vulnerability class. The telemetry Stealthium collects to catch it is the same telemetry that surfaces cryptojacking, unauthorised inference, model weight exfiltration, and cross-tenant VRAM side-channel attacks, amongst others. These are not theoretical. They are happening, and they are invisible to every security tool currently deployed on GPU infrastructure.
The reason is architectural, not a gap in signatures or tuning. Your existing stack has no instrumentation below the CPU. From its perspective, a legitimate training job and an attacker draining your VRAM look identical.
GPU compute is now the most valuable, least monitored layer in modern infrastructure. The attack surface is being actively explored. The framework coverage does not exist yet. The window between vulnerability disclosure and fleet-wide patching is measured in weeks.
Observable, secure, and controllable GPU infrastructure is not a nice-to-have. It is the compensating control that exists while everything else catches up.
Hope is not a strategy.
If you are running GPU infrastructure, whether for training, inference, deploying models or real-time rendering, you are operating with a blind spot that attackers are actively learning to exploit. The question is not whether your stack can detect GPUBreach. It is what else it is missing that you do not know about yet.
See Stealthium in action. Book a demo.
Research attribution: This analysis is based on the GPUBreach research paper from the University of Toronto (Chris S. Lin, Yuqin Yan, Guozhen Ding, Joyce Qu, Joseph Zhu, David Lie, Gururaj Saileshwar), presented at IEEE S&P 2026. Responsibly disclosed to NVIDIA, Google, AWS, and Microsoft.
Related reading: